import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from statsmodels.tsa.ar_model import AutoReg
from statsmodels.tsa.arima.model import ARIMAConsider the AR(2) equation:
Show that it has a causal stationary solution. Write the solution explicitly in terms of .
The characteristic polynomial corresponding to this equation is: . Its roots are easily seen to be whose modulus equals 2. Since the modulus is strictly larger than 1, this AR(2) equation admits a causal stationary solution. To express the solution explicitly in terms of , we first write:
so that
A simpler expression for can be obtained using the following. Let and . Check that
where
We thus have
The above expression represents the given causal stationary AR(2) process as an infinite order MA (MA(∞)) process.
There is an inbuilt statsmodels function (shown below) which gives the MA(∞) representation of every casual stationary ARMA process.
from statsmodels.tsa.arima_process import ArmaProcess
ar = [1, -0.5, 0.25] # these are the phi-coefficients of the given AR process
ma = [1]
# these are the theta-coefficients of the ARMA process
# (since we are dealing with a pure AR process, there is no theta coefficient)
AR2_process = ArmaProcess(ar, ma)
nlags = 20
ma_infinity = AR2_process.arma2ma(lags=nlags) # this gives \psi_j, j = 0, \dots, lags-1
psi_j = np.array([
(2 / np.sqrt(3)) * (0.5) ** j * np.sin((j + 1) * np.pi / 3)
for j in range(nlags)
])
print(np.column_stack([psi_j, ma_infinity]))[[ 1.00000000e+00 1.00000000e+00]
[ 5.00000000e-01 5.00000000e-01]
[ 3.53525080e-17 0.00000000e+00]
[-1.25000000e-01 -1.25000000e-01]
[-6.25000000e-02 -6.25000000e-02]
[-8.83812699e-18 0.00000000e+00]
[ 1.56250000e-02 1.56250000e-02]
[ 7.81250000e-03 7.81250000e-03]
[ 1.65714881e-18 0.00000000e+00]
[-1.95312500e-03 -1.95312500e-03]
[-9.76562500e-04 -9.76562500e-04]
[-2.76191468e-19 0.00000000e+00]
[ 2.44140625e-04 2.44140625e-04]
[ 1.22070313e-04 1.22070312e-04]
[ 1.68347800e-19 0.00000000e+00]
[-3.05175781e-05 -3.05175781e-05]
[-1.52587891e-05 -1.52587891e-05]
[-6.47323754e-21 0.00000000e+00]
[ 3.81469727e-06 3.81469727e-06]
[ 1.90734863e-06 1.90734863e-06]]
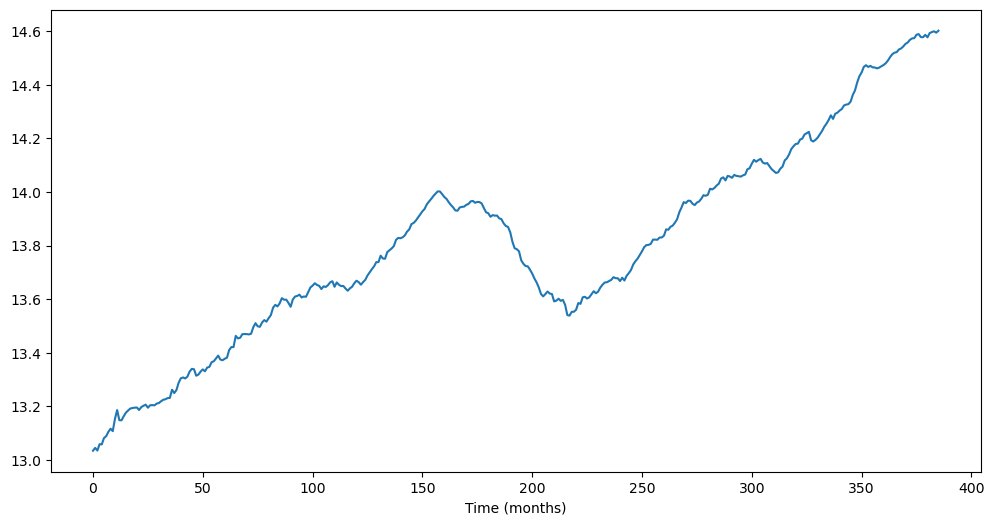
TTLCONS (Total Construction Spending Data)¶
In Lecture 22, we fit ARIMA models to the following dataset.
ttlcons = pd.read_csv('TTLCONS_14April2025.csv')
print(ttlcons.head())
y = np.log(ttlcons['TTLCONS']) # note that we are taking logarithms
print(len(y))
plt.figure(figsize = (12, 6))
plt.plot(y)
plt.xlabel('Time (months)')
plt.show()
observation_date TTLCONS
0 1993-01-01 458080
1 1993-02-01 462967
2 1993-03-01 458399
3 1993-04-01 469425
4 1993-05-01 468998
386
We fitted the following models to (here is log of the data from FRED)
- AR(3) for :
- ARIMA(3, 1, 0) for : (the only difference betwen this model and the previous one is the absence of the term)
- ARIMA(0, 2, 1) for :
- ARIMA(3, 2, 2) for :
Note that there is no intercept term in models 2, 3, and 4.
Here is the code for fitting each of these models.
Model One¶
We will difference the data and then fit the AR(3) model. This can be done in two ways. Either we can use AutoReg or ARIMA(3, 0, 0).
mod1_AutoReg = AutoReg(np.diff(y), lags=3).fit()
print(mod1_AutoReg.summary())
# AutoReg uses OLS (also known as conditional MLE) for parameter estimation.
# Alternatively, we can use ARIMA(3, 0, 0). This method uses the full MLE:
mod1 = ARIMA(np.diff(y), order=(3, 0, 0), trend='c').fit()
print(mod1.summary())
# Both these methods give similar but slightly different answers:
print(np.column_stack([mod1_AutoReg.params, mod1.params[:-1]]))
# From this output, we can see that the estimate of the intercept is slightly different (almost double)
# but the remaining estimates are almost the same.
AutoReg Model Results
==============================================================================
Dep. Variable: y No. Observations: 385
Model: AutoReg(3) Log Likelihood 1179.667
Method: Conditional MLE S.D. of innovations 0.011
Date: Fri, 18 Apr 2025 AIC -2349.335
Time: 09:33:42 BIC -2329.608
Sample: 3 HQIC -2341.509
385
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
const 0.0021 0.001 3.302 0.001 0.001 0.003
y.L1 0.2148 0.050 4.309 0.000 0.117 0.313
y.L2 0.0636 0.051 1.252 0.211 -0.036 0.163
y.L3 0.2014 0.050 4.047 0.000 0.104 0.299
Roots
=============================================================================
Real Imaginary Modulus Frequency
-----------------------------------------------------------------------------
AR.1 1.4139 -0.0000j 1.4139 -0.0000
AR.2 -0.8648 -1.6626j 1.8741 -0.3263
AR.3 -0.8648 +1.6626j 1.8741 0.3263
-----------------------------------------------------------------------------
SARIMAX Results
==============================================================================
Dep. Variable: y No. Observations: 385
Model: ARIMA(3, 0, 0) Log Likelihood 1187.247
Date: Fri, 18 Apr 2025 AIC -2364.495
Time: 09:33:42 BIC -2344.729
Sample: 0 HQIC -2356.656
- 385
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
const 0.0041 0.001 3.693 0.000 0.002 0.006
ar.L1 0.2148 0.046 4.717 0.000 0.126 0.304
ar.L2 0.0636 0.045 1.425 0.154 -0.024 0.151
ar.L3 0.2014 0.048 4.199 0.000 0.107 0.295
sigma2 0.0001 7.2e-06 17.040 0.000 0.000 0.000
===================================================================================
Ljung-Box (L1) (Q): 0.14 Jarque-Bera (JB): 43.88
Prob(Q): 0.70 Prob(JB): 0.00
Heteroskedasticity (H): 0.50 Skew: -0.27
Prob(H) (two-sided): 0.00 Kurtosis: 4.56
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
[[0.00207946 0.00407175]
[0.21484133 0.21483792]
[0.0635657 0.06356862]
[0.20137871 0.20137351]]
The main difference between the parameter estimates from the two different versions of fitting AR(3) to is in the intercept estimate (0.0021 vs 0.0041). But the two parameter estimates lead to almost the same predictions. In the code below, predictions are first obtained for the differenced data, and then for the original data.
n = len(y)
k = 100
fcast_diff_1 = mod1_AutoReg.get_prediction(start=n-1, end=n+k-2).predicted_mean
# these are the forecasts for the differenced data
last_observed_y = y.iloc[-1]
fcast_1 = np.zeros(k)
fcast_1[0] = last_observed_y + fcast_diff_1[0]
for i in range(1, k):
fcast_1[i] = fcast_1[i-1] + fcast_diff_1[i]Next we obtain the forecasts using mod1 (which was fitted using ARIMA(3, 0, 0)).
n = len(y)
k = 100
fcast_diff_1_arima = mod1.get_prediction(start=n-1, end=n+k-2).predicted_mean
# these are the forecasts for the differenced data
last_observed_y = y.iloc[-1]
fcast_1_arima = np.zeros(k)
fcast_1_arima[0] = last_observed_y + fcast_diff_1_arima[0]
for i in range(1, k):
fcast_1_arima[i] = fcast_1_arima[i-1] + fcast_diff_1_arima[i]tme = range(1, n+1)
tme_future = range(n+1, n+k+1)
plt.figure(figsize = (12, 7))
plt.plot(tme, np.exp(y), label = 'Data')
plt.plot(tme_future, np.exp(fcast_1), label = 'Forecast (Model One (AutoReg))', color = 'black')
plt.plot(tme_future, np.exp(fcast_1_arima), label = 'Forecast (Model One (ARIMA))', color = 'red')
plt.axvline(x=n, color='gray', linestyle='--')
plt.legend()
plt.show()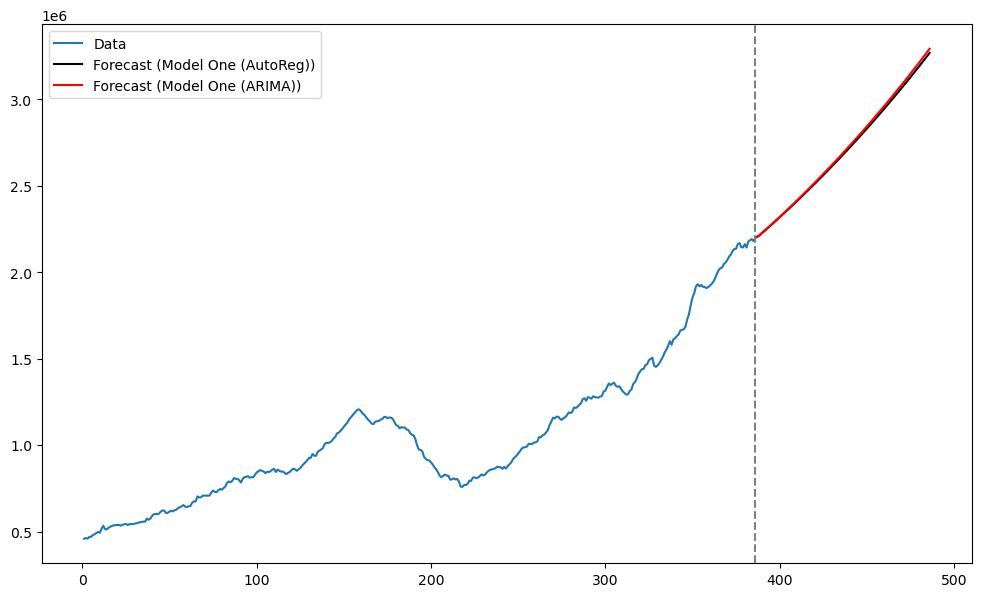
One can ask if Model One can be fit directly to the original data via ARIMA(3, 1, 0). This function, by default, will not include an intercept term (i.e., it will fit Model Two). To use the intercept term for the differenced data, one needs to supply the argument ‘t’ for trend as follows.
mod1_arima = ARIMA(y, order=(3, 1, 0), trend='t').fit()
print(mod1_arima.summary()) SARIMAX Results
==============================================================================
Dep. Variable: TTLCONS No. Observations: 386
Model: ARIMA(3, 1, 0) Log Likelihood 1187.247
Date: Fri, 18 Apr 2025 AIC -2364.495
Time: 09:33:42 BIC -2344.729
Sample: 0 HQIC -2356.656
- 386
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
x1 0.0041 0.001 3.693 0.000 0.002 0.006
ar.L1 0.2148 0.046 4.717 0.000 0.126 0.304
ar.L2 0.0636 0.045 1.425 0.154 -0.024 0.151
ar.L3 0.2014 0.048 4.199 0.000 0.107 0.295
sigma2 0.0001 7.2e-06 17.040 0.000 0.000 0.000
===================================================================================
Ljung-Box (L1) (Q): 0.14 Jarque-Bera (JB): 43.88
Prob(Q): 0.70 Prob(JB): 0.00
Heteroskedasticity (H): 0.50 Skew: -0.27
Prob(H) (two-sided): 0.00 Kurtosis: 4.56
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
The output above is basically the same as the output for mod1 (ARIMA(3, 0, 0) applied to diff(y)). With this models, predictions are obtained directly for the original data and there is no need for post-processing to convert them into predictions for the original series.
fcast_y_arima = mod1_arima.get_prediction(start=n, end=n+k-1).predicted_mean
plt.figure(figsize = (12, 7))
plt.plot(tme, np.exp(y), label = 'Data')
plt.plot(tme_future, np.exp(fcast_1), label = 'Forecast (Model One (AutoReg))', color = 'black')
plt.plot(tme_future, np.exp(fcast_1_arima), label = 'Forecast (Model One (ARIMA(3, 0, 0) for diff(y)))', color = 'red')
plt.plot(tme_future, np.exp(fcast_y_arima), label = 'Forecast (Model One (ARIMA(3, 1, 0) for y))', color = 'green')
plt.axvline(x=n, color='gray', linestyle='--')
plt.legend()
plt.show()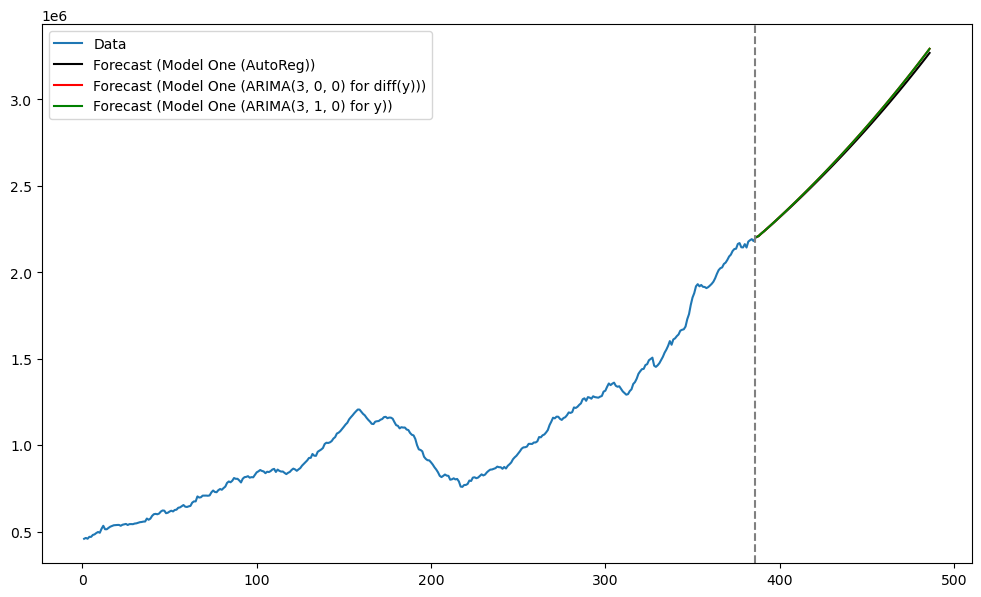
The predictions are basically the same for the three versions of fitting Model One.
Model Two¶
Next we move to Model Two which we fit by applying ARIMA(3, 1, 0) directly to (there is no need to provide any special argument as in trend = ‘’).
mod2 = ARIMA(y, order=(3, 1, 0)).fit()
print(mod2.summary())
SARIMAX Results
==============================================================================
Dep. Variable: TTLCONS No. Observations: 386
Model: ARIMA(3, 1, 0) Log Likelihood 1181.467
Date: Fri, 18 Apr 2025 AIC -2354.934
Time: 09:33:42 BIC -2339.121
Sample: 0 HQIC -2348.662
- 386
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ar.L1 0.2497 0.047 5.316 0.000 0.158 0.342
ar.L2 0.0941 0.042 2.216 0.027 0.011 0.177
ar.L3 0.2363 0.046 5.127 0.000 0.146 0.327
sigma2 0.0001 7.58e-06 16.661 0.000 0.000 0.000
===================================================================================
Ljung-Box (L1) (Q): 1.02 Jarque-Bera (JB): 47.32
Prob(Q): 0.31 Prob(JB): 0.00
Heteroskedasticity (H): 0.51 Skew: -0.27
Prob(H) (two-sided): 0.00 Kurtosis: 4.63
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
This model does not fit a constant term, as can be seen from the regression output above. This lack of constant term affects predictions quite strongly, as seen below.
fcast_2 = mod2.get_prediction(start=n, end=n+k-1).predicted_mean
plt.figure(figsize = (12, 7))
plt.plot(tme, np.exp(y), label = 'Data')
plt.plot(tme_future, np.exp(fcast_y_arima), label = 'Forecast (Model One)', color = 'black')
plt.plot(tme_future, np.exp(fcast_2), label = 'Forecast (Model Two)', color = 'red')
plt.axvline(x=n, color='gray', linestyle='--')
plt.legend()
plt.show()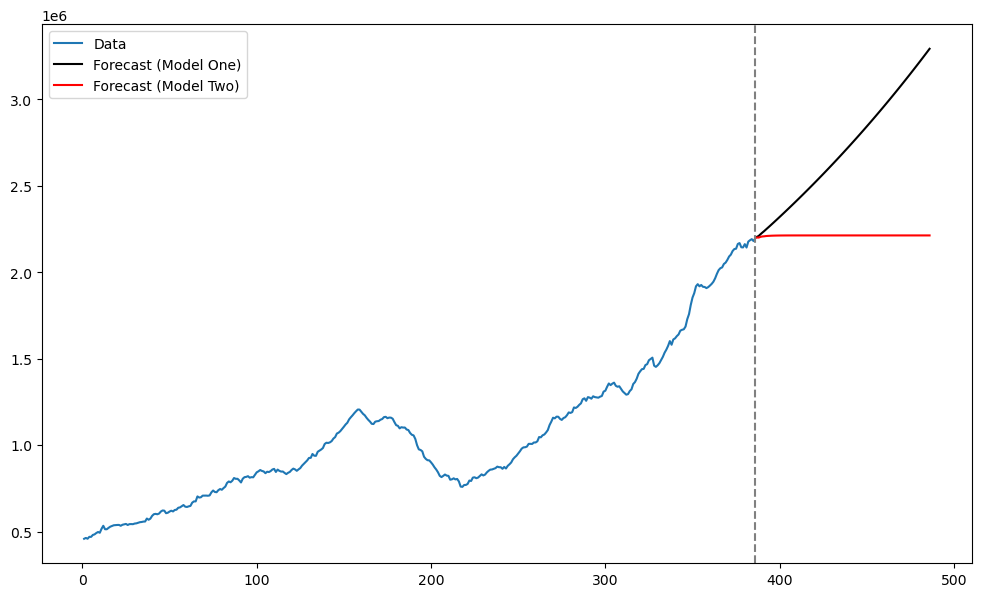
The lack of the intercept term provides bad predictions.
Model Three¶
Next we fit Model Three ARIMA(0, 2, 1) to .
mod3 = ARIMA(y, order=(0, 2, 1)).fit()
fcast_3 = mod3.get_prediction(start=n, end=n+k-1).predicted_mean
plt.figure(figsize = (12, 7))
plt.plot(tme, np.exp(y), label = 'Data')
plt.plot(tme_future, np.exp(fcast_y_arima), label = 'Forecast (Model One)', color = 'black')
plt.plot(tme_future, np.exp(fcast_2), label = 'Forecast (Model Two)', color = 'red')
plt.plot(tme_future, np.exp(fcast_3), label = 'Forecast (Model Three)', color = 'green')
plt.axvline(x=n, color='gray', linestyle='--')
plt.legend()
plt.show()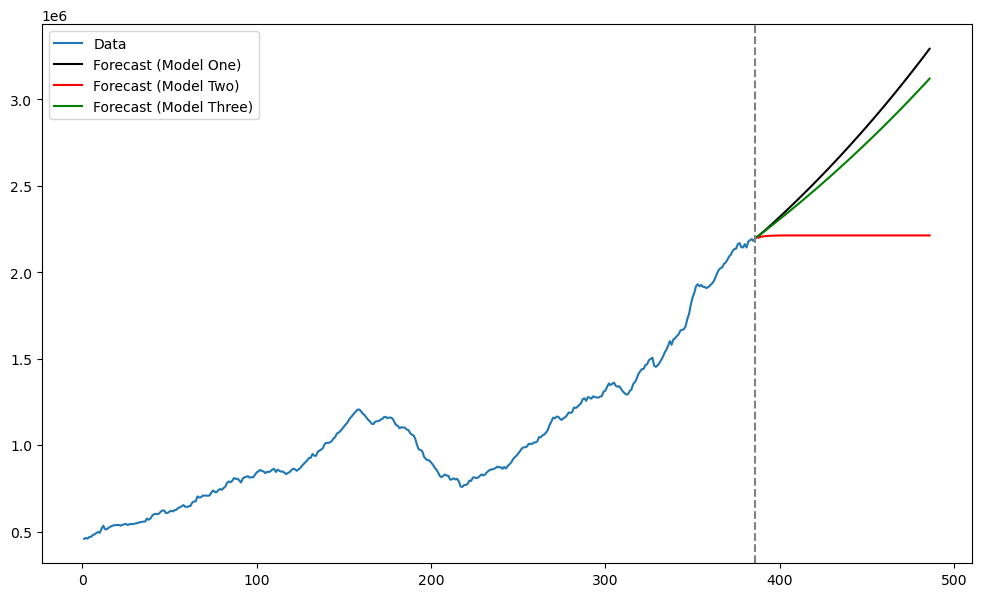
Models one and three give somewhat similar predictions.
Model Four¶
We fit Model Four by using ARIMA(3, 2, 2) on .
mod4 = ARIMA(y, order=(3, 2, 2)).fit()
fcast_4 = mod4.get_prediction(start=n, end=n+k-1).predicted_mean
plt.figure(figsize = (12, 7))
plt.plot(tme, np.exp(y), label = 'Data')
plt.plot(tme_future, np.exp(fcast_y_arima), label = 'Forecast (Model One)', color = 'black')
plt.plot(tme_future, np.exp(fcast_2), label = 'Forecast (Model Two)', color = 'red')
plt.plot(tme_future, np.exp(fcast_3), label = 'Forecast (Model Three)', color = 'green')
plt.plot(tme_future, np.exp(fcast_4), label = 'Forecast (Model Four)', color = 'blue')
plt.axvline(x=n, color='gray', linestyle='--')
plt.legend()
plt.show()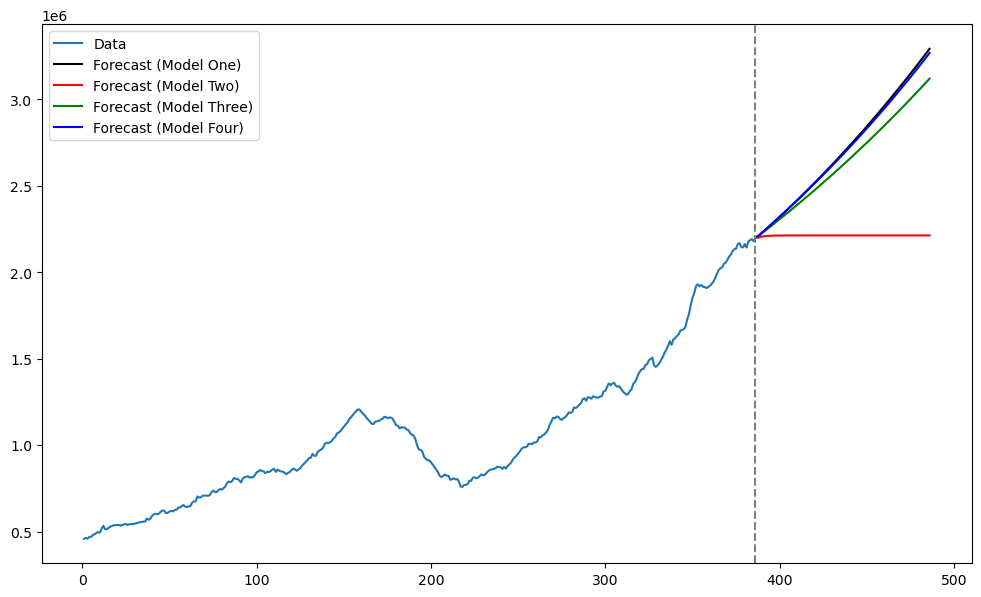
Comparison between Model One and Model Four:¶
Models 1 and 4 give essentially the same forecast. They appear quite different: Model 1 is AR(3) with intercept applied to diff(y) while Model 4 is ARMA(3, 2) applied to diff(diff(y)) (twice differenced data) without intercept. Why are they giving the same forecast?
print(mod4.summary()) SARIMAX Results
==============================================================================
Dep. Variable: TTLCONS No. Observations: 386
Model: ARIMA(3, 2, 2) Log Likelihood 1184.165
Date: Fri, 18 Apr 2025 AIC -2356.331
Time: 09:33:43 BIC -2332.627
Sample: 0 HQIC -2346.929
- 386
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ar.L1 0.0428 0.592 0.072 0.942 -1.117 1.203
ar.L2 -0.0126 0.071 -0.177 0.860 -0.152 0.127
ar.L3 0.1041 0.062 1.691 0.091 -0.017 0.225
ma.L1 -0.8459 0.602 -1.405 0.160 -2.026 0.334
ma.L2 -0.0603 0.532 -0.113 0.910 -1.102 0.982
sigma2 0.0001 7.51e-06 16.259 0.000 0.000 0.000
===================================================================================
Ljung-Box (L1) (Q): 0.01 Jarque-Bera (JB): 40.35
Prob(Q): 0.93 Prob(JB): 0.00
Heteroskedasticity (H): 0.54 Skew: -0.21
Prob(H) (two-sided): 0.00 Kurtosis: 4.53
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
AIC and BIC¶
In lectures this week, we used AIC and BIC to do model selection. The formulae for AIC and BIC are:
and
Let us compute these for each of the models and check if the answer matches the one given by the model function.
n = len(y)
mod1_aic_formula = -2 * mod1_arima.llf + 2 * len(mod1_arima.params)
mod1_bic_formula = -2 * mod1_arima.llf + (np.log(n - 1)) * len(mod1_arima.params)
print(mod1_aic_formula, mod1_arima.aic)
print(mod1_bic_formula, mod1_arima.bic)
# Note that we have used (n - 1) for sample size in the calculation for BIC
# because this model is really applied to the differenced data and there are n - 1 first differences-2364.494873895399 -2364.494873895399
-2344.72865722396 -2344.72865722396
n = len(y)
mod2_aic_formula = -2 * mod2.llf + 2 * len(mod2.params)
mod2_bic_formula = -2 * mod2.llf + (np.log(n - 1)) * len(mod2.params)
print(mod2_aic_formula, mod2.aic)
print(mod2_bic_formula, mod2.bic)
-2354.933614650533 -2354.933614650533
-2339.120641313382 -2339.120641313382
n = len(y)
mod3_aic_formula = -2 * mod3.llf + 2 * len(mod3.params)
mod3_bic_formula = -2 * mod3.llf + (np.log(n - 2)) * len(mod3.params)
print(mod3_aic_formula, mod3.aic)
print(mod3_bic_formula, mod3.bic)
# Now we are using (n - 2) for sample size in the calculation of BIC
# because this model is applied to the twice-differenced data and there are n - 2 second order differences.
-2357.3214233532403 -2357.3214233532403
-2349.420138248065 -2349.420138248065
n = len(y)
mod4_aic_formula = -2 * mod4.llf + 2 * len(mod4.params)
mod4_bic_formula = -2 * mod4.llf + (np.log(n - 2)) * len(mod4.params)
print(mod4_aic_formula, mod4.aic)
print(mod4_bic_formula, mod4.bic)
# Again we are using (n - 2) for sample size in the calculation of BIC
# because this model is applied to the twice-differenced data and there are n - 2 second order differences.
-2356.33062605351 -2356.33062605351
-2332.626770737984 -2332.626770737984