import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
import cvxpy as cp
import yfinance as yfThree High-Dimensional Models for Time Series¶
We shall discuss three simple high-dimensional models for time series. The first model was already studied in the previous week. The third model is the same as the spectrum model from last lecture (even though the presentation today will be slightly different). The second model has not been discussed before in this class but it is quite simple.
Model ONE¶
This is the model
where (which can be interpreted as the trend function) is smooth in . can be estimated from the data using one of the following two regularized estimators obtained by minimizing
or
As we saw previously, these are the same as the estimators obtained by employing the ridge and LASSO penalties to the high-dimensional linear regression model:
def smoothfun(x):
ans = np.sin(15*x) + np.exp(-(x ** 2)/2) + 0.5*((x - 0.5) ** 2) + 2*np.log(x + 0.1)
return ans
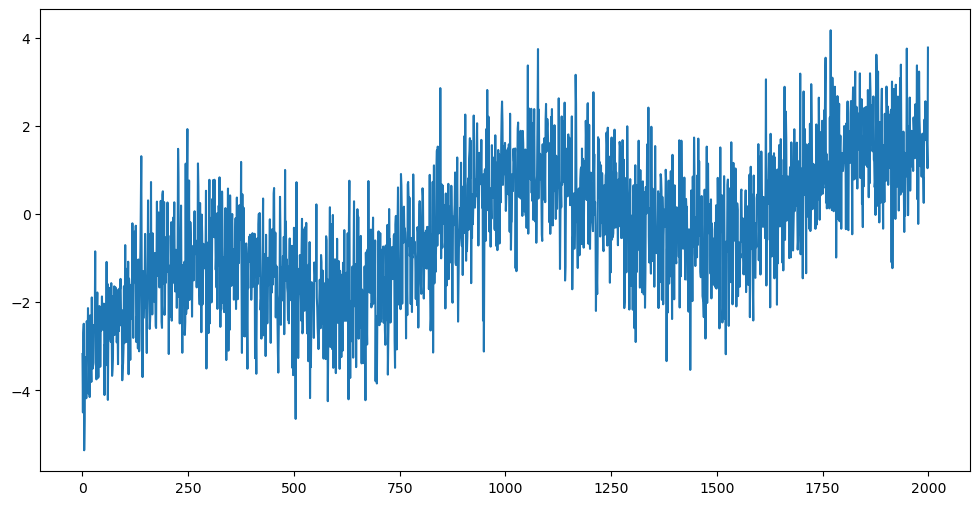
n = 2000
xx = np.linspace(0, 1, n)
mu_true = np.array([smoothfun(x) for x in xx])
sig = 1
rng = np.random.default_rng(seed = 42)
errorsamples = rng.normal(loc = 0, scale = sig, size = n)
y = mu_true + errorsamples
plt.figure(figsize = (12, 6))
plt.plot(y)
plt.show()
Below we compute the estimator directly without going to the regression representation (with the matrix that we previously used). We use the optimization functions from cvxpy directly on the optimization in terms of .
def mu_est_ridge(y, lambda_val):
n = len(y)
mu = cp.Variable(n)
neg_likelihood_term = cp.sum((y - mu)**2)
smoothness_penalty = cp.sum(cp.square(mu[2:] - 2 * mu[1:-1] + mu[:-2]))
objective = cp.Minimize(neg_likelihood_term + lambda_val * smoothness_penalty)
problem = cp.Problem(objective)
problem.solve()
return mu.value
def mu_est_lasso(y, lambda_val):
n = len(y)
mu = cp.Variable(n)
neg_likelihood_term = cp.sum((y - mu)**2)
smoothness_penalty = cp.sum(cp.abs(mu[2:] - 2 * mu[1:-1] + mu[:-2]))
objective = cp.Minimize(neg_likelihood_term + lambda_val * smoothness_penalty)
problem = cp.Problem(objective)
problem.solve()
return mu.value
mu_opt_ridge = mu_est_ridge(y, 200000)
mu_opt_lasso = mu_est_lasso(y, 200)
plt.figure(figsize = (12, 6))
plt.plot(y, label = 'Data', color = 'lightgray')
plt.plot(mu_opt_ridge, label = 'ridge')
plt.plot(mu_true, color = 'red', label = 'true')
plt.plot(mu_opt_lasso, color = 'black', label = 'lasso')
plt.legend()
plt.show()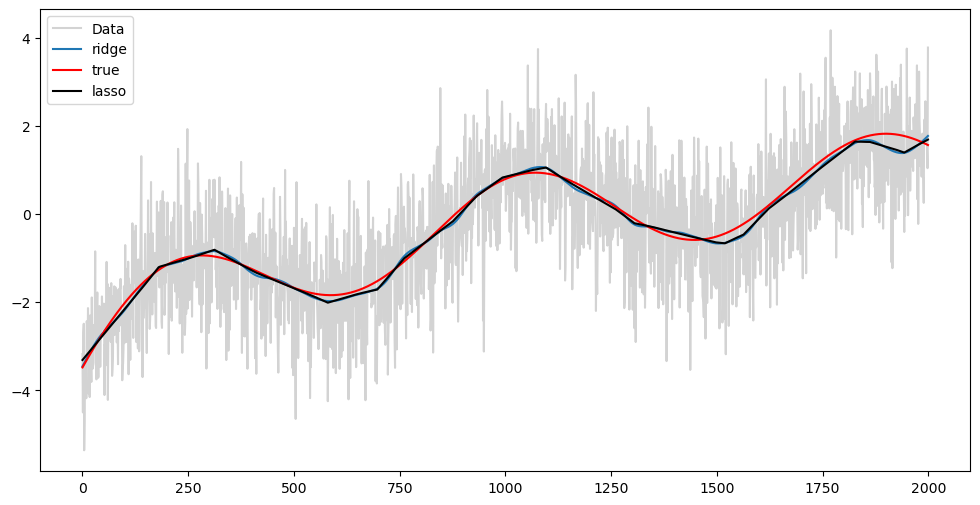
Model TWO¶
This is the model
Negative log-likelihood parametrized by is given by
We add regularization and minimize:
or
def alpha_est_ridge(y, lambda_val):
n = len(y)
alpha = cp.Variable(n)
neg_likelihood_term = cp.sum(cp.multiply(((y ** 2)/2), cp.exp(-2 * alpha)) + alpha)
smoothness_penalty = cp.sum(cp.square(alpha[2:] - 2 * alpha[1:-1] + alpha[:-2]))
objective = cp.Minimize(neg_likelihood_term + lambda_val * smoothness_penalty)
problem = cp.Problem(objective)
problem.solve()
return alpha.value
def alpha_est_lasso(y, lambda_val):
n = len(y)
alpha = cp.Variable(n)
neg_likelihood_term = cp.sum(cp.multiply(((y ** 2)/2), cp.exp(-2 * alpha)) + alpha)
smoothness_penalty = cp.sum(cp.abs(alpha[2:] - 2 * alpha[1:-1] + alpha[:-2]))
objective = cp.Minimize(neg_likelihood_term + lambda_val * smoothness_penalty)
problem = cp.Problem(objective)
problem.solve()
return alpha.valueBelow we describe two simulation settings for this model.
Simulation 1 for Model 2¶
#Simulate data from this variance model:
n = 400
tvals = np.arange(1, n+1)
th = -0.8
tau_t = np.sqrt((1 + (th ** 2) + 2*th*np.cos(2 * np.pi * (tvals)/n))) #this is a smooth function of t
y = rng.normal(loc = 0, scale = tau_t)
plt.figure(figsize = (12, 6))
plt.plot(y)
plt.show()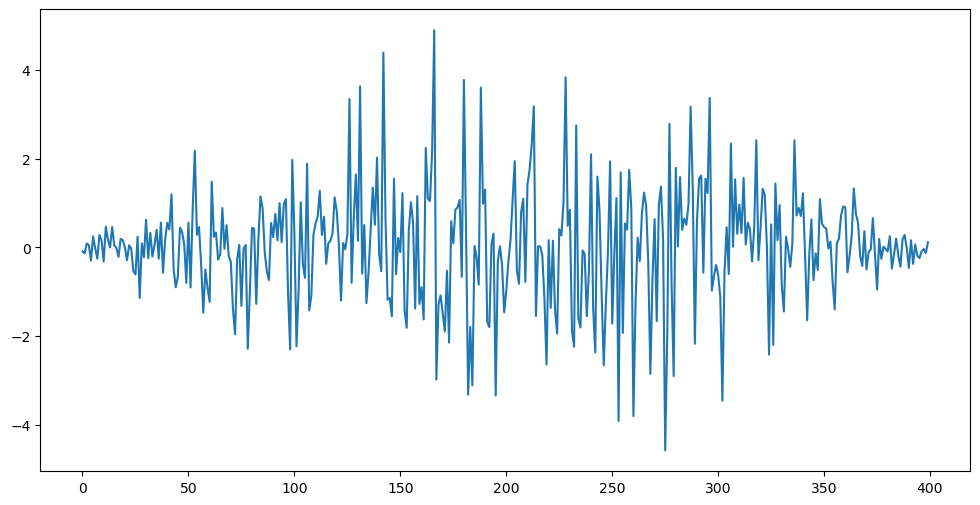
alpha_true = np.log(tau_t)
alpha_opt_ridge = alpha_est_ridge(y, 2000000)
alpha_opt_lasso = alpha_est_lasso(y, 200)
plt.figure(figsize = (12, 6))
plt.plot(alpha_opt_ridge, label = 'ridge')
plt.plot(alpha_true, color = 'red', label = 'true')
plt.plot(alpha_opt_lasso, color = 'black', label = 'lasso')
plt.legend()
plt.show()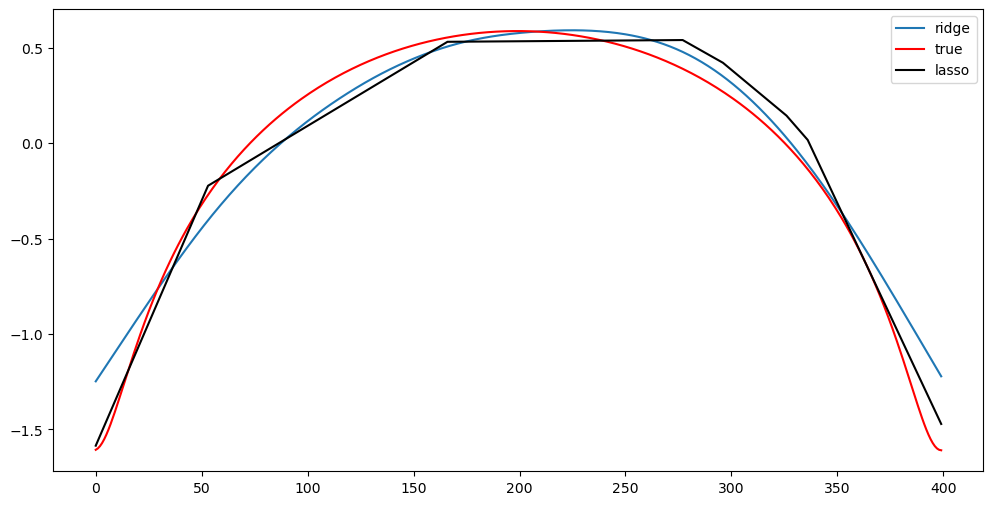
The sufficient statistic in this model is . Because , the mean of equals and its variance is . Below we plot as well as .
#Plotting y^2 against tau^2
plt.figure(figsize = (12, 6))
plt.plot(y ** 2, label = 'Data', color = 'lightgray')
plt.plot(tau_t ** 2, color = 'blue', label = 'Truth')
plt.plot(np.exp(2*alpha_opt_ridge), color = 'red', label = 'Ridge')
plt.plot(np.exp(2*alpha_opt_lasso), color = 'black', label = 'LASSO')
plt.legend()
plt.show()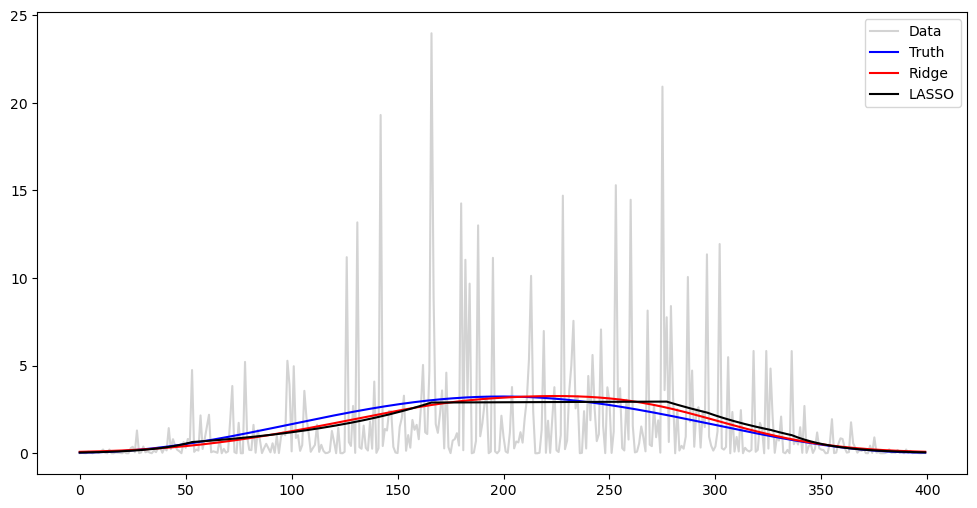
Observe from the above plot that both the level (mean) of as well as its variance changes with . This is because the mean of equals , and its variance equals .
Because , we can write
The mean of is negative (internet says it is about -1.27). This means that if we plot and in one figure, most of the values for will appear to be below .
#Plotting log y^2 against log tau^2
plt.figure(figsize = (12, 6))
plt.plot(np.log(y ** 2), color = 'lightgray', label = 'Data')
plt.plot(np.log(tau_t ** 2), color = 'blue', label = 'Truth')
plt.plot(np.log(np.exp(2*alpha_opt_ridge)), color = 'red', label = 'Ridge')
plt.plot(np.log(np.exp(2*alpha_opt_lasso)), color = 'black', label = 'LASSO')
plt.legend()
plt.show()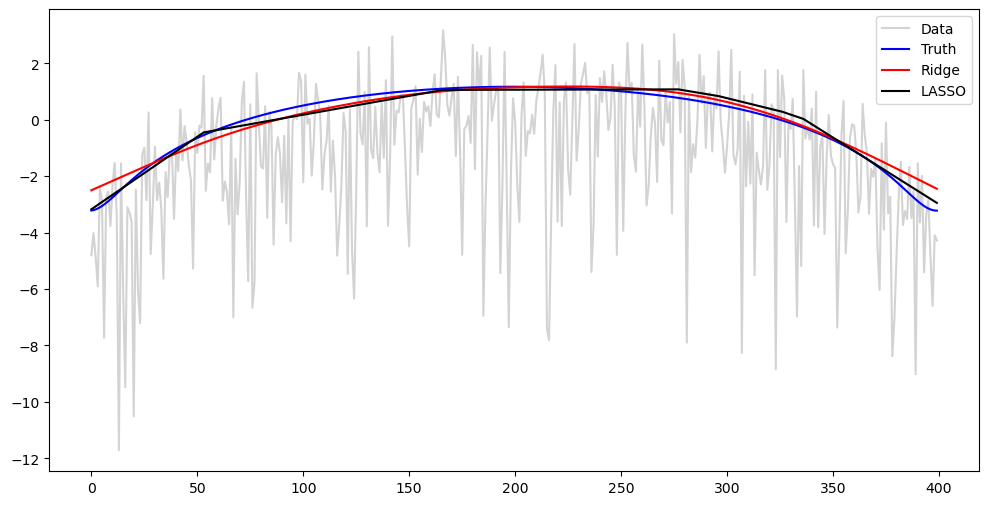
Simulation 2 for Model 2¶
Here is the second simulation setting for this model.
def smoothfun(x):
ans = np.sin(15*x) + np.exp(-(x ** 2)/2) + 0.5*((x - 0.5) ** 2) + 2*np.log(x + 0.1)
return ans
n = 2000
xx = np.linspace(0, 1, n)
alpha_true = np.array([smoothfun(x) for x in xx])
plt.figure(figsize = (12, 6))
plt.plot(alpha_true)
plt.show()
tau_t = np.exp(alpha_true)
y = rng.normal(loc = 0, scale = tau_t)
plt.figure(figsize = (12, 6))
plt.plot(y)
plt.show()
alpha_opt_ridge = alpha_est_ridge(y, 40000)
alpha_opt_lasso = alpha_est_lasso(y, 200)
plt.figure(figsize = (12, 6))
plt.plot(alpha_opt_ridge, label = 'ridge')
plt.plot(alpha_true, color = 'red', label = 'true')
plt.plot(alpha_opt_lasso, color = 'black', label = 'lasso')
plt.legend()
plt.show()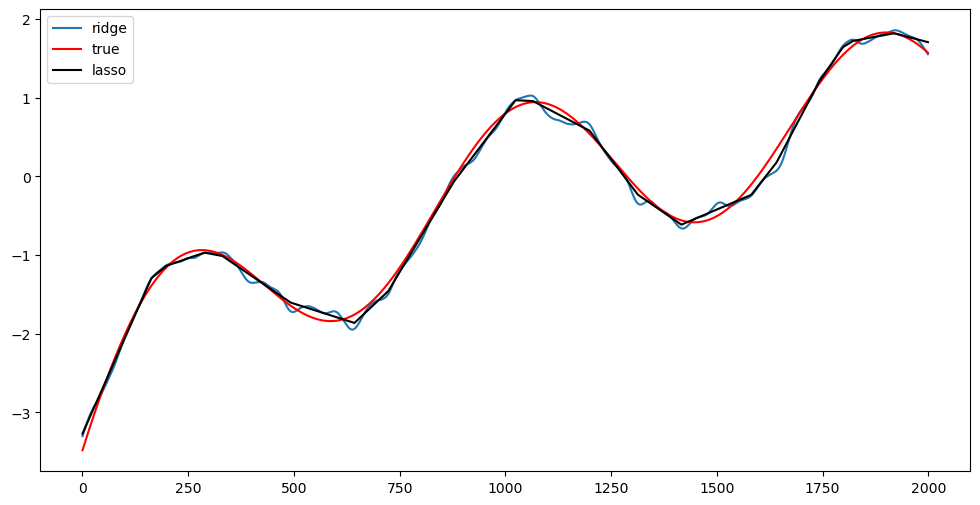
#Plotting y^2 against tau^2
plt.figure(figsize = (12, 6))
plt.plot(y ** 2, label = 'Data', color = 'lightgray')
plt.plot(tau_t ** 2, color = 'blue', label = 'Truth')
plt.plot(np.exp(2*alpha_opt_ridge), color = 'red', label = 'Ridge')
plt.plot(np.exp(2*alpha_opt_lasso), color = 'black', label = 'LASSO')
plt.legend()
plt.show()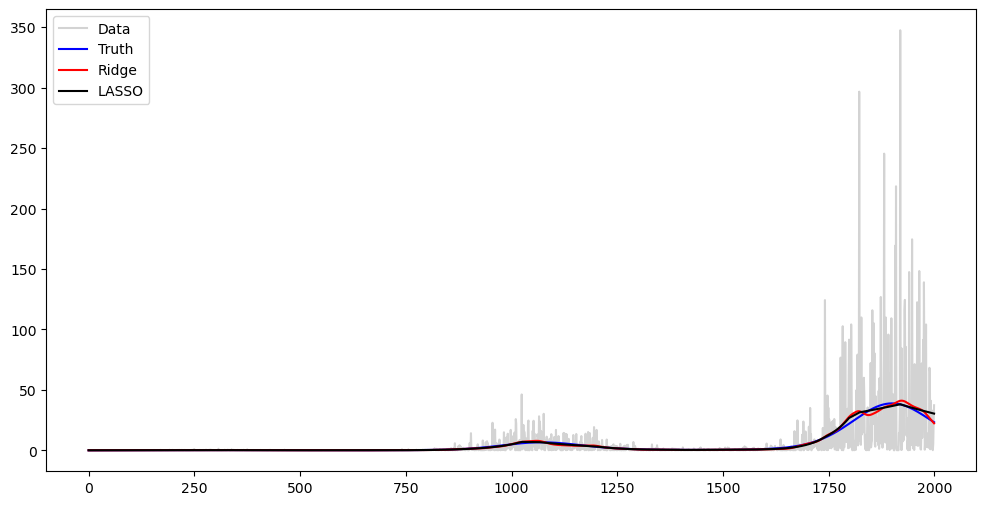
#Plotting log y^2 against log tau^2
plt.figure(figsize = (12, 6))
plt.plot(np.log(y ** 2), color = 'lightgray', label = 'Data')
plt.plot(np.log(tau_t ** 2), color = 'blue', label = 'Truth')
plt.plot(np.log(np.exp(2*alpha_opt_ridge)), color = 'red', label = 'Ridge')
plt.plot(np.log(np.exp(2*alpha_opt_lasso)), color = 'black', label = 'LASSO')
plt.legend()
plt.show()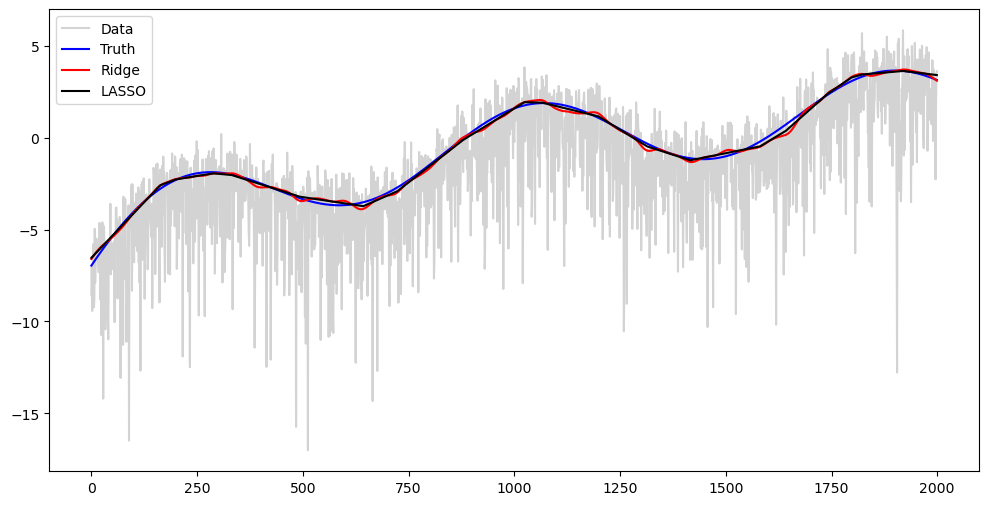
A real dataset from finance for which Model 2 is applicable¶
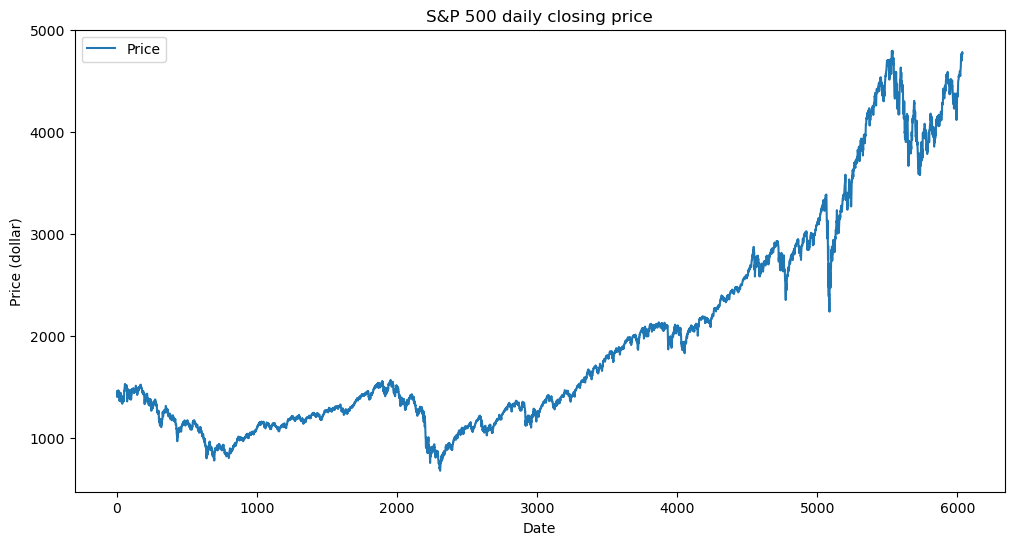
Next, we examine a real dataset where this variance model (Model 2) may be applicable. The dataset consists of stock price data for the S&P 500 mutual fund, downloaded from Yahoo Finance using the yfinance library.
# Download S&P 500 data
sp500 = yf.download('^GSPC', start='2000-01-01', end='2024-01-01')
sp500_closeprice = sp500['Close'].to_numpy().flatten() #this is the daily closing price of the S&P 500 index
plt.figure(figsize=(12,6))
plt.plot(sp500_closeprice, label="Price")
plt.xlabel("Date")
plt.title("S&P 500 daily closing price")
plt.ylabel("Price (dollar)")
plt.legend()
plt.show()
[*********************100%***********************] 1 of 1 completed
Instead of working with the prices directly, we work with percentage daily returns.
log_prices = np.log(sp500_closeprice)
y = 100 * np.diff(log_prices) #these are the percentage daily returns
plt.figure(figsize = (12, 6))
plt.plot(y)
plt.title('SNP Daily Percentage Returns')
plt.show()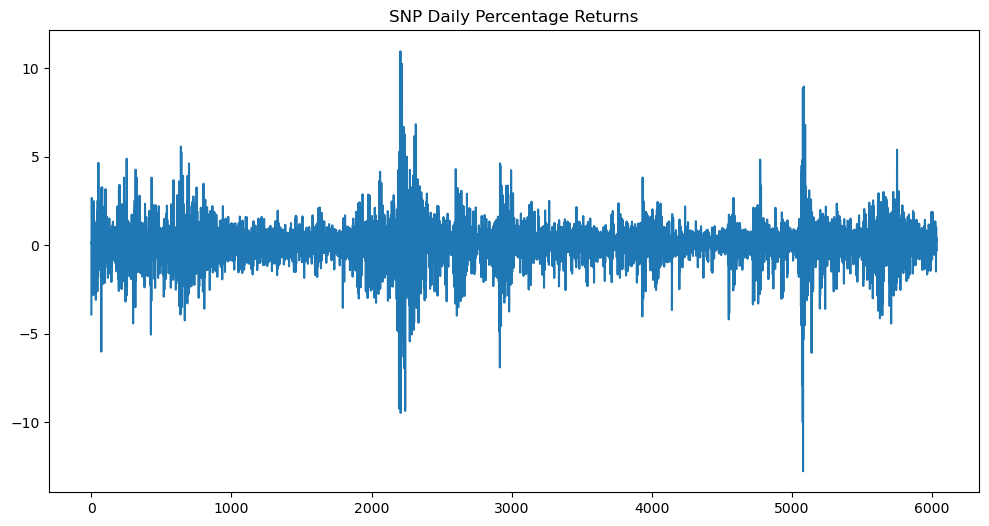
The plot above suggests that Model 2 might be useful for this dataset.
alpha_opt_ridge = alpha_est_ridge(y, 40000000)
alpha_opt_lasso = alpha_est_lasso(y, 2000)
plt.figure(figsize = (12, 6))
plt.plot(alpha_opt_ridge, label = 'ridge')
plt.plot(alpha_opt_lasso, color = 'black', label = 'lasso')
plt.legend()
plt.show()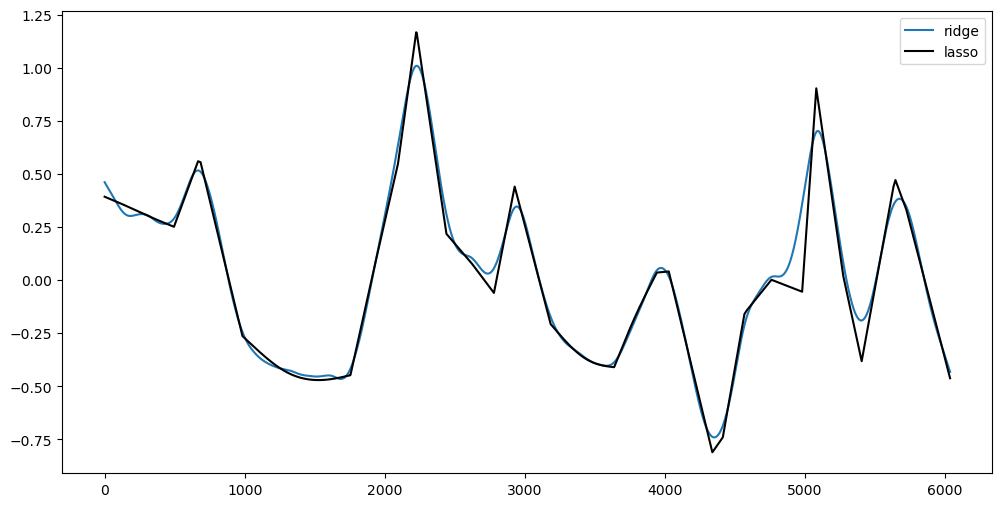
#Plotting y^2 against tau^2
plt.figure(figsize = (12, 6))
plt.plot(y ** 2, label = 'Data', color = 'lightblue')
plt.plot(np.exp(2*alpha_opt_ridge), color = 'red', label = 'Ridge')
plt.plot(np.exp(2*alpha_opt_lasso), color = 'black', label = 'LASSO')
plt.legend()
plt.show()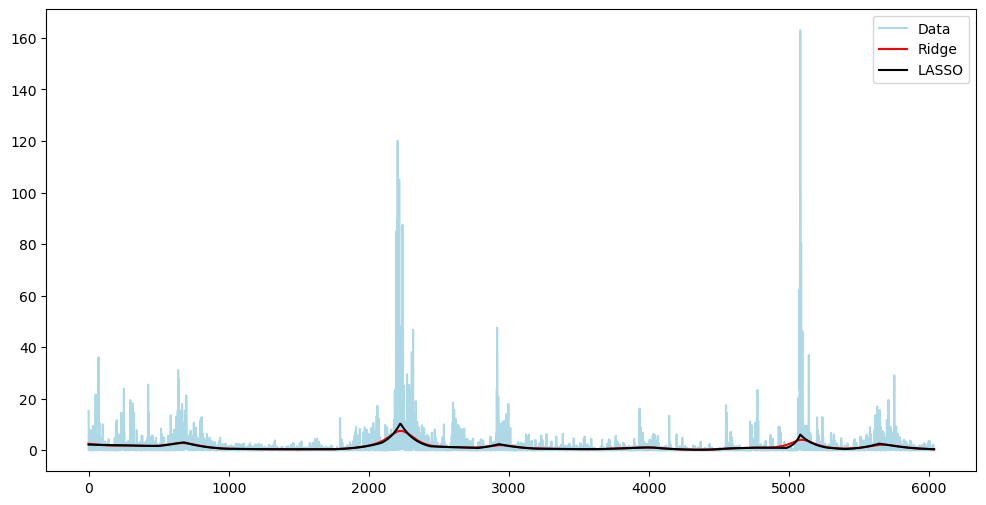
#Plotting log y^2 against log tau^2
plt.figure(figsize = (12, 6))
plt.plot(2*np.log(np.abs(y) + 1e-8), color = 'lightblue', label = 'Data') #small value added to np.abs(y) to prevent taking logs of zeros
plt.plot(np.log(np.exp(2*alpha_opt_ridge)), color = 'red', label = 'Ridge')
plt.plot(np.log(np.exp(2*alpha_opt_lasso)), color = 'black', label = 'LASSO')
plt.legend()
plt.show()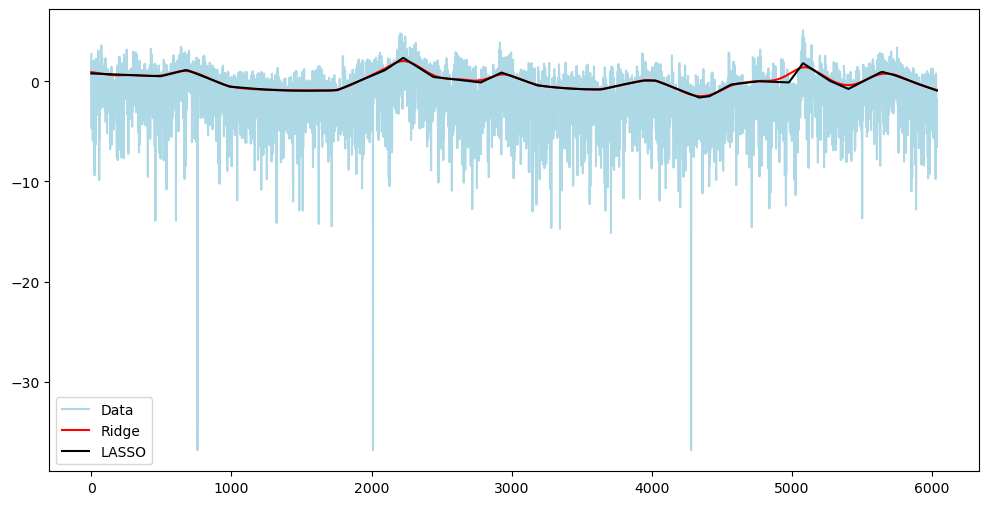
Model THREE¶
Model 3 is
for where is the DFT coefficient of the observed data .
Likelihood in terms of the periodogram is:
Negative log-likelihood is
Letting , we can rewrite the above as
Minimizing this without any regularization on leads to
We will use regularization and estimate (and ) by minimizing:
or
Code for computing these estimators is given below. These functions (spectrum_estimator_ridge and spectrum_estimator_lasso) use and λ as input. In the first step, one computes the periodogram as the optimization is in terms of the periodogram. We apply these methods to the sunspots dataset.
sunspots = pd.read_csv('SN_y_tot_V2.0.csv', header = None, sep = ';')
y = sunspots.iloc[:,1].values
n = len(y)
plt.figure(figsize = (10, 6))
plt.plot(y)
plt.show()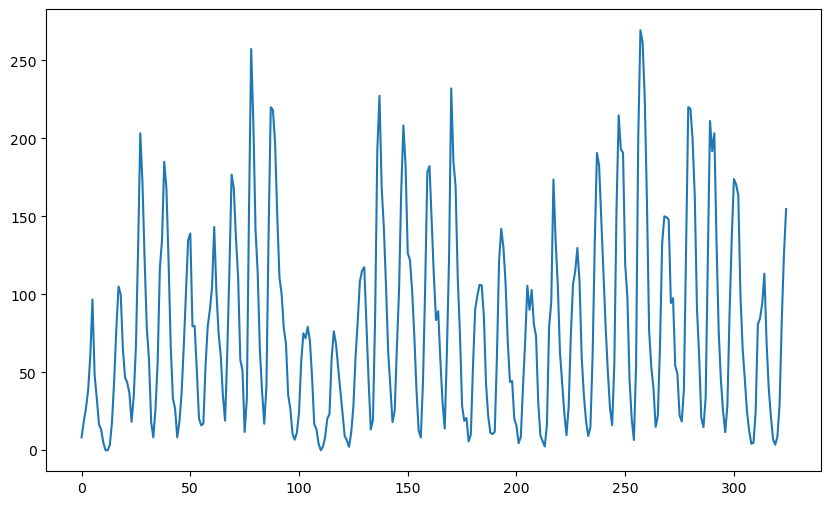
def periodogram(y):
fft_y = np.fft.fft(y)
n = len(y)
fourier_freqs = np.arange(1/n, 1/2, 1/n)
m = len(fourier_freqs)
pgram_y = (np.abs(fft_y[1:m+1]) ** 2)/n
return fourier_freqs, pgram_yfreqs, pgram = periodogram(y)
plt.figure(figsize = (12, 6))
markerline, stemline, baseline = plt.stem(freqs, pgram)
markerline.set_marker("None")
plt.title('Periodogram')
plt.show()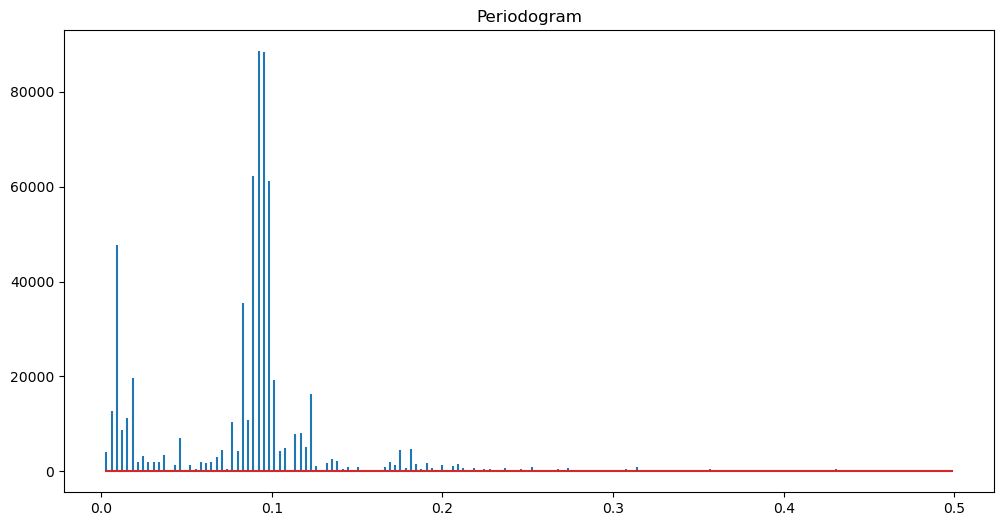
plt.figure(figsize = (12, 6))
markerline, stemline, baseline = plt.stem(freqs, np.log(pgram))
markerline.set_marker("None")
plt.title('Logarithm of the Periodogram')
plt.show()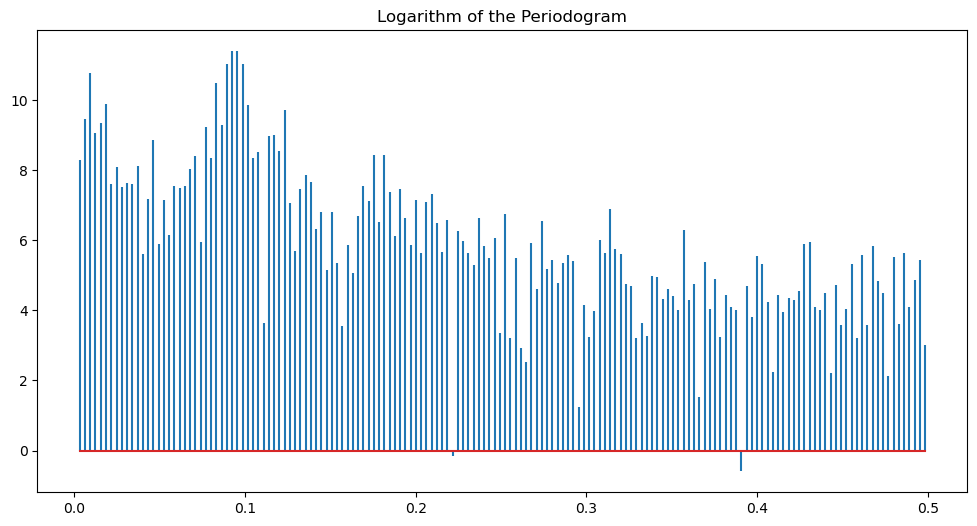
def spectrum_estimator_ridge(y, lambda_val):
freq, I = periodogram(y)
m = len(freq)
n = len(y)
alpha = cp.Variable(m)
neg_likelihood_term = cp.sum(cp.multiply((n * I / 2), cp.exp(-2 * alpha)) + 2*alpha)
smoothness_penalty = cp.sum(cp.square(alpha[2:] - 2 * alpha[1:-1] + alpha[:-2]))
objective = cp.Minimize(neg_likelihood_term + lambda_val * smoothness_penalty)
problem = cp.Problem(objective)
problem.solve()
return alpha.value, freq
def spectrum_estimator_lasso(y, lambda_val):
freq, I = periodogram(y)
m = len(freq)
n = len(y)
alpha = cp.Variable(m)
neg_likelihood_term = cp.sum(cp.multiply((n * I / 2), cp.exp(-2 * alpha)) + 2*alpha)
smoothness_penalty = cp.sum(cp.abs(alpha[2:] - 2 * alpha[1:-1] + alpha[:-2]))
objective = cp.Minimize(neg_likelihood_term + lambda_val * smoothness_penalty)
problem = cp.Problem(objective)
problem.solve()
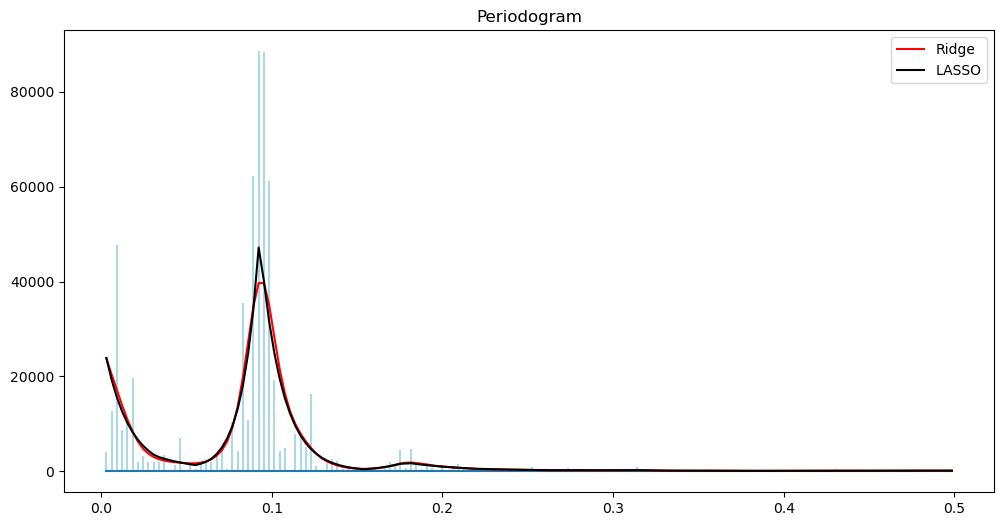
return alpha.value, freqAfter computing the estimators using the above code, we can the periodogram and its logarithm along with suitable estimates. The mean of according to the model is
alpha_opt_ridge, freq = spectrum_estimator_ridge(y, 100)
pgram_mean_ridge = (2/n)*(np.exp(2*alpha_opt_ridge))
alpha_opt_lasso, freq = spectrum_estimator_lasso(y, 10)
pgram_mean_lasso = (2/n)*(np.exp(2*alpha_opt_lasso))
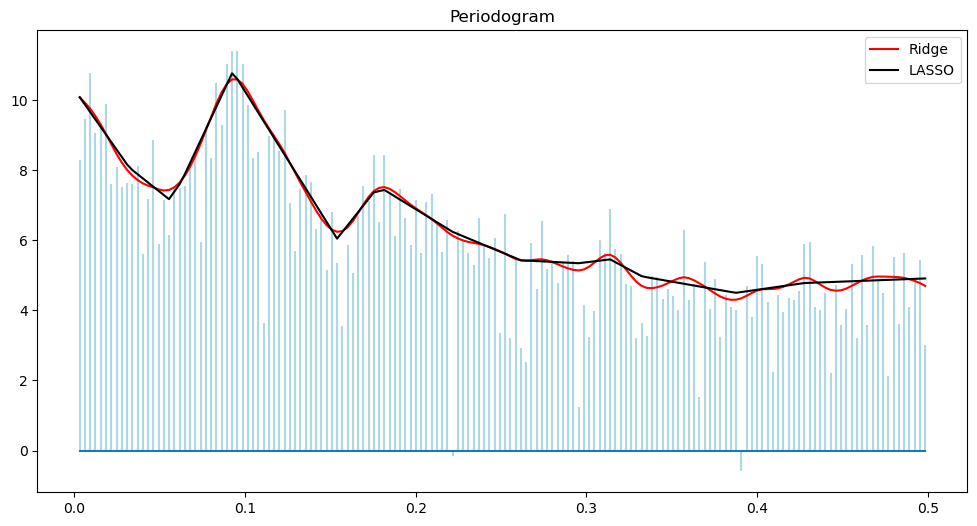
plt.figure(figsize = (12, 6))
markerline, stemline, baseline = plt.stem(freq, pgram, linefmt = 'lightblue', basefmt = '')
markerline.set_marker("None")
plt.title('Periodogram')
plt.plot(freq, pgram_mean_ridge, color = 'red', label = 'Ridge')
plt.plot(freq, pgram_mean_lasso, color = 'black', label = "LASSO")
plt.legend()
plt.show()
plt.figure(figsize = (12, 6))
markerline, stemline, baseline = plt.stem(freq, np.log(pgram), linefmt = 'lightblue', basefmt = '')
markerline.set_marker("None")
plt.title('Periodogram')
plt.plot(freq, np.log(pgram_mean_ridge), color = 'red', label = 'Ridge')
plt.plot(freq, np.log(pgram_mean_lasso), color = 'black', label = "LASSO")
plt.legend()
plt.show()