import pandas as pd
import numpy as np
import statsmodels.api as sm
import matplotlib.pyplot as plt
import cvxpy as cpLet us consider the temperature anomalies dataset that we already used in the last lecture.
temp_jan = pd.read_csv('TempAnomalies_January_Feb2025.csv', skiprows=4)
print(temp_jan.head())
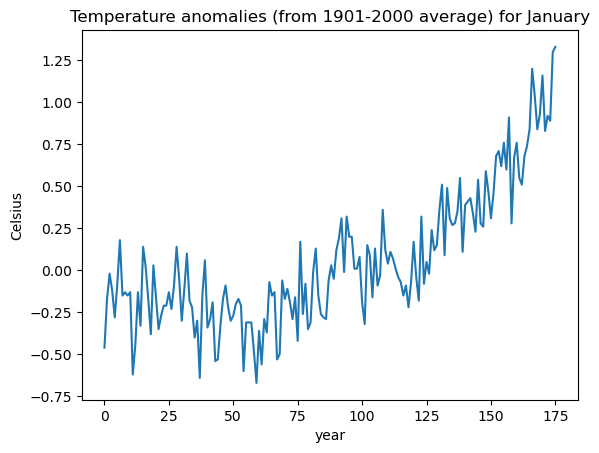
y = temp_jan['Anomaly']
plt.plot(y)
plt.xlabel('year')
plt.ylabel('Celsius')
plt.title('Temperature anomalies (from 1901-2000 average) for January')
plt.show() Year Anomaly
0 1850 -0.46
1 1851 -0.17
2 1852 -0.02
3 1853 -0.12
4 1854 -0.28
The matrix for our high-dimensional regression model is calculated as follows.
n = len(y)
x = np.arange(1, n+1)
X = np.column_stack([np.ones(n), x-1])
for i in range(n-2):
c = i+2
xc = ((x > c).astype(float))*(x-c)
X = np.column_stack([X, xc])
print(X)[[ 1. 0. -0. ... -0. -0. -0.]
[ 1. 1. 0. ... -0. -0. -0.]
[ 1. 2. 1. ... -0. -0. -0.]
...
[ 1. 173. 172. ... 1. 0. -0.]
[ 1. 174. 173. ... 2. 1. 0.]
[ 1. 175. 174. ... 3. 2. 1.]]
Given fixed values of τ and σ, the posterior mean of β is given by:
where is the diagonal matrix with diagonals . This is computed below.
# Posterior mean of beta with fixed tau and sig
C = 10**4
#tau = 0.001
tau = .0001
sig = 0.2
Q = np.diag(np.concatenate([[C, C], np.repeat(tau**2, n-2)]))
XTX = np.dot(X.T, X)
TempMat = np.linalg.inv(np.linalg.inv(Q) + (XTX/(sig ** 2)))
XTy = np.dot(X.T, y)
betahat = np.dot(TempMat, XTy/(sig ** 2))
muhat = np.dot(X, betahat)
plt.figure(figsize = (10, 6))
plt.plot(y)
plt.plot(muhat)
plt.show()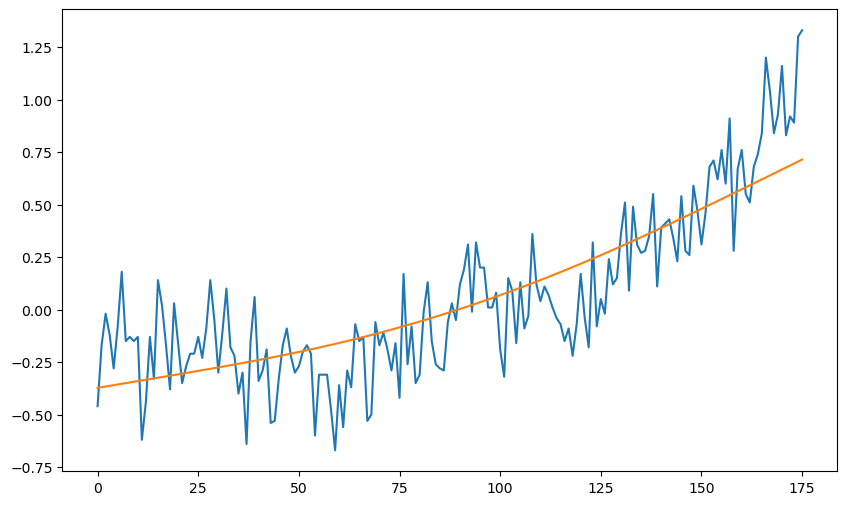
We showed in class that this posterior mean coincides with the ridge regression estimate from last lecture provided . This can be verified as follows.
#below penalty_start = 2 means that b0 and b1 are not included in the penalty
def solve_ridge(X, y, lambda_val, penalty_start=2):
n, p = X.shape
# Define variable
beta = cp.Variable(p)
# Define objective
loss = cp.sum_squares(X @ beta - y)
reg = lambda_val * cp.sum_squares(beta[penalty_start:])
objective = cp.Minimize(loss + reg)
# Solve problem
prob = cp.Problem(objective)
prob.solve()
return beta.valueb_ridge = solve_ridge(X, y, lambda_val = (sig ** 2)/(tau ** 2))
ridge_fitted = np.dot(X, b_ridge)
plt.figure(figsize = (10, 6))
plt.plot(y, color = 'lightgray', label = 'data')
plt.plot(ridge_fitted, color = 'red', label = 'Ridge')
plt.plot(muhat, color = 'blue', label = 'Posterior mean')
plt.legend()
plt.show()
We next perform posterior inference for all the parameters . We follow the method described in lecture. First we take a grid of values of τ and σ and compute the posterior (on the logarithmic scale) of τ and σ.
tau_gr = np.logspace(np.log10(0.0001), np.log10(1), 100)
sig_gr = np.logspace(np.log10(0.1), np.log10(1), 100)
#sig_gr = np.array([0.16])
t, s = np.meshgrid(tau_gr, sig_gr)
g = pd.DataFrame({'tau': t.flatten(), 'sig': s.flatten()})
for i in range(len(g)):
tau = g.loc[i, 'tau']
sig = g.loc[i, 'sig']
Q = np.diag(np.concatenate([[C, C], np.repeat(tau**2, n-2)]))
Mat = np.linalg.inv(Q) + (X.T @ X)/(sig ** 2)
Matinv = np.linalg.inv(Mat)
sgn, logcovdet = np.linalg.slogdet(Matinv)
sgnQ, logcovdetQ = np.linalg.slogdet(Q)
g.loc[i, 'logpost'] = (-n-1)*np.log(sig) - np.log(tau) - 0.5 * logcovdetQ + 0.5 * logcovdet - ((np.sum(y ** 2))/(2*(sig ** 2))) + (y.T @ X @ Matinv @ X.T @ y)/(2 * (sig ** 4))
Point estimates of τ and σ can be obtained either by maximizers of the posterior or posterior means.
#Posterior maximizers:
max_row = g['logpost'].idxmax()
print(max_row)
tau_opt = g.loc[max_row, 'tau']
sig_opt = g.loc[max_row, 'sig']
print(tau_opt, sig_opt)
2333
0.0021544346900318843 0.1707352647470691
Below, we fix τ and σ to be the posterior maximizers, and then find the posterior mean of β.
# Posterior mean of beta with tau_opt and sig_opt
C = 10**4
tau = tau_opt
sig = sig_opt
Q = np.diag(np.concatenate([[C, C], np.repeat(tau**2, n-2)]))
XTX = np.dot(X.T, X)
TempMat = np.linalg.inv(np.linalg.inv(Q) + (XTX/(sig ** 2)))
XTy = np.dot(X.T, y)
betahat = np.dot(TempMat, XTy/(sig ** 2))
muhat = np.dot(X, betahat)
plt.figure(figsize = (10, 6))
plt.plot(y)
plt.plot(muhat)
plt.show()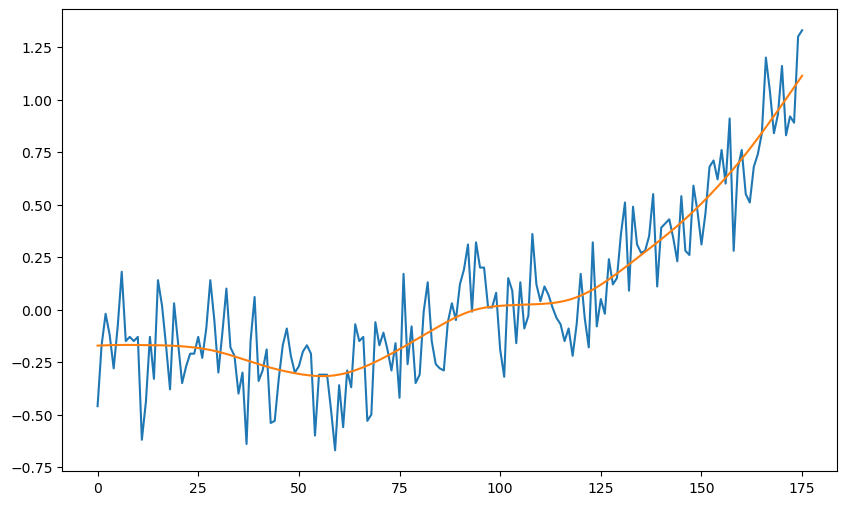
Below we conver the log-posterior values to posterior values.
g['post'] = np.exp(g['logpost'] - np.max(g['logpost']))
g['post'] = g['post']/np.sum(g['post'])print(g.head(10)) tau sig logpost post
0 0.000100 0.1 -4.745616 4.468373e-91
1 0.000110 0.1 6.770660 4.483372e-86
2 0.000120 0.1 17.552952 2.159208e-81
3 0.000132 0.1 27.530407 4.649950e-77
4 0.000145 0.1 36.672379 4.342662e-73
5 0.000159 0.1 44.983468 1.766918e-69
6 0.000175 0.1 52.496662 3.237092e-66
7 0.000192 0.1 59.265711 2.817835e-63
8 0.000210 0.1 65.357670 1.246292e-60
9 0.000231 0.1 70.846229 3.014883e-58
We can now compute posterior means of τ and σ.
tau_pm = np.sum(g['tau'] * g['post'])
sig_pm = np.sum(g['sig'] * g['post'])
print(tau_pm, sig_pm)0.0024208108011471072 0.1732583012438226
Posterior means are quite close to the posterior maximizers obtained previously.
Below we compute posterior samples of all the parameters .
N = 1000
samples = g.sample(N, weights = g['post'], replace = True)
tau_samples = np.array(samples.iloc[:,0])
sig_samples = np.array(samples.iloc[:,1])
betahats = np.zeros((n, N))
muhats = np.zeros((n, N))
for i in range(N):
tau = tau_samples[i]
sig = sig_samples[i]
Q = np.diag(np.concatenate([[C, C], np.repeat(tau**2, n-2)]))
XTX = np.dot(X.T, X)
TempMat = np.linalg.inv(np.linalg.inv(Q) + (XTX/(sig ** 2)))
XTy = np.dot(X.T, y)
betahat = np.dot(TempMat, XTy/(sig ** 2))
muhat = np.dot(X, betahat)
betahats[:,i] = betahat
muhats[:,i] = muhatFrom these samples, we can obtain approximations of the posterior means of β and the fitted values .
beta_est = np.mean(betahats, axis = 1)
mu_est = np.mean(muhats, axis = 1) #these are the fitted valuesBelow we plot the fitted values corresponding to the samples of β.
plt.figure(figsize = (10, 6))
plt.plot(y, label = 'Data')
for i in range(N):
plt.plot(muhats[:,i], color = 'red')
plt.plot(mu_est, color = 'black', label = 'Posterior Mean')
plt.legend()
plt.show()
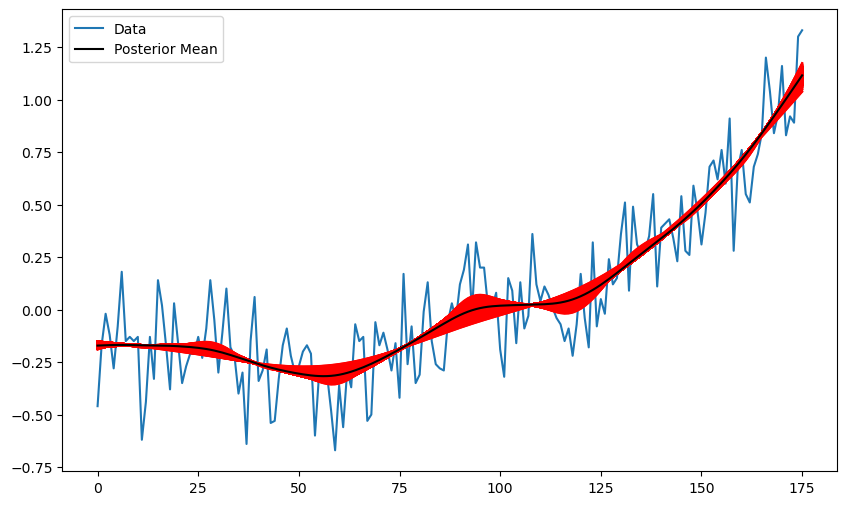
It is interesting that the uncertainty band is narrow at some time points and wider in others.
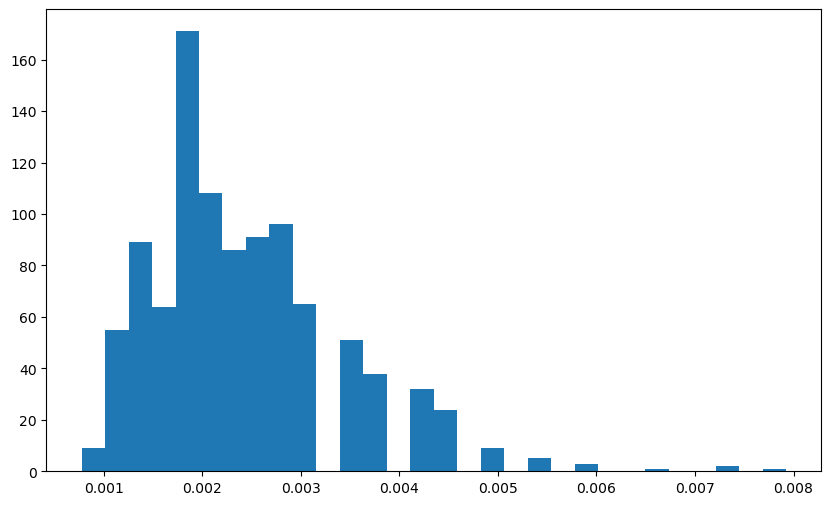
Below are histograms of the samples of τ and σ.
plt.figure(figsize=(10, 6))
plt.hist(tau_samples, bins=30)
plt.show()
plt.figure(figsize=(10, 6))
plt.hist(sig_samples, bins=30)
plt.show()
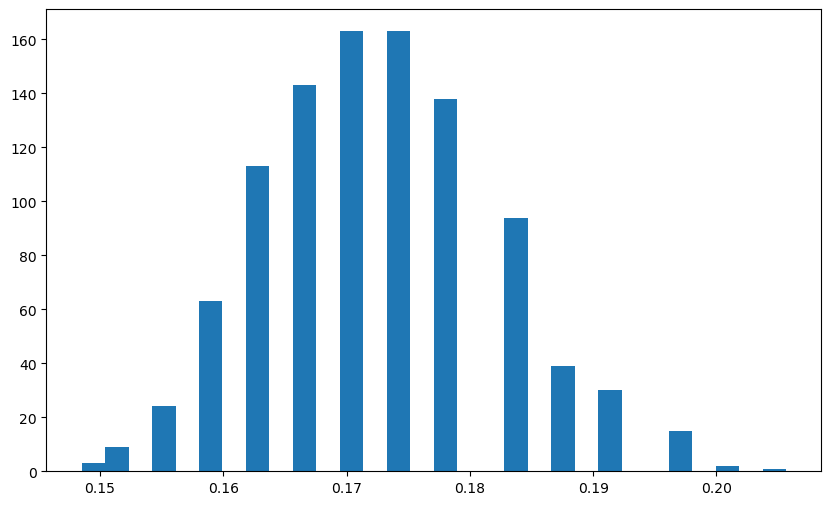
It is quite interesting that the posterior samples of τ correspond to values that are neither too large (wiggly function fits) and neither too small (almost-linear function fits).